
Pozrite si
Podľa vedcov je pokrok v hĺbkovom učení silne závislý od výkonu výpočtovej techniky a ten sa nezadržateľne blíži k svojim limitom. Ďalšie napredovanie bude možné prostredníctvom zmien v existujúcich technológiách alebo pomocou doteraz neobjavených metód.
Výskumníci z Massachusetts Institute of Technology, Underwood International College a University of Brasilia v nedávnej štúdii konštatovali, že výrazné napredovanie v hĺbkovom učení nie je možné bez dramatického zvyšovania počítačového výkonu.
Čo je to hĺbkové učenie?
Hlboké učenie je čiastkové pole strojového učenia týkajúce sa algoritmov inšpirovaných štruktúrou a funkciou mozgu.Voláme ich umelé neurónové siete, pozostávajú z funkcií neurónov, umiestnených vo vrstvách prinášajúcich signály do ďalších neurónov.
Tieto signály sú produktom vstupných údajov privádzaných do siete a prechádzajú z jednej vrstvy na druhú, pomaly „naladia“ sieť. V skutočnosti však upravujú synaptickú silu hmotnosti každého spojenia. Sieť sa napkon naučí robiť predpovede extrahovaním funkcií zo súboru údajov a identifikáciou krížových výberových trendov.
Vedci v štúdii analyzovali viac ako tisíc príspevkov zo servera Arxiv.org, ale aj ďalších referenčných zdrojov, aby pochopili súvislosť medzi hĺbkovým vzdelávacím výkonom a výpočtami. Mimoriadnu pozornosť venovali doménam vrátane klasifikácie obrázkov, detekcie objektov, odpovedania na otázky, rozpoznávanie názvov entít a strojového prekladu.
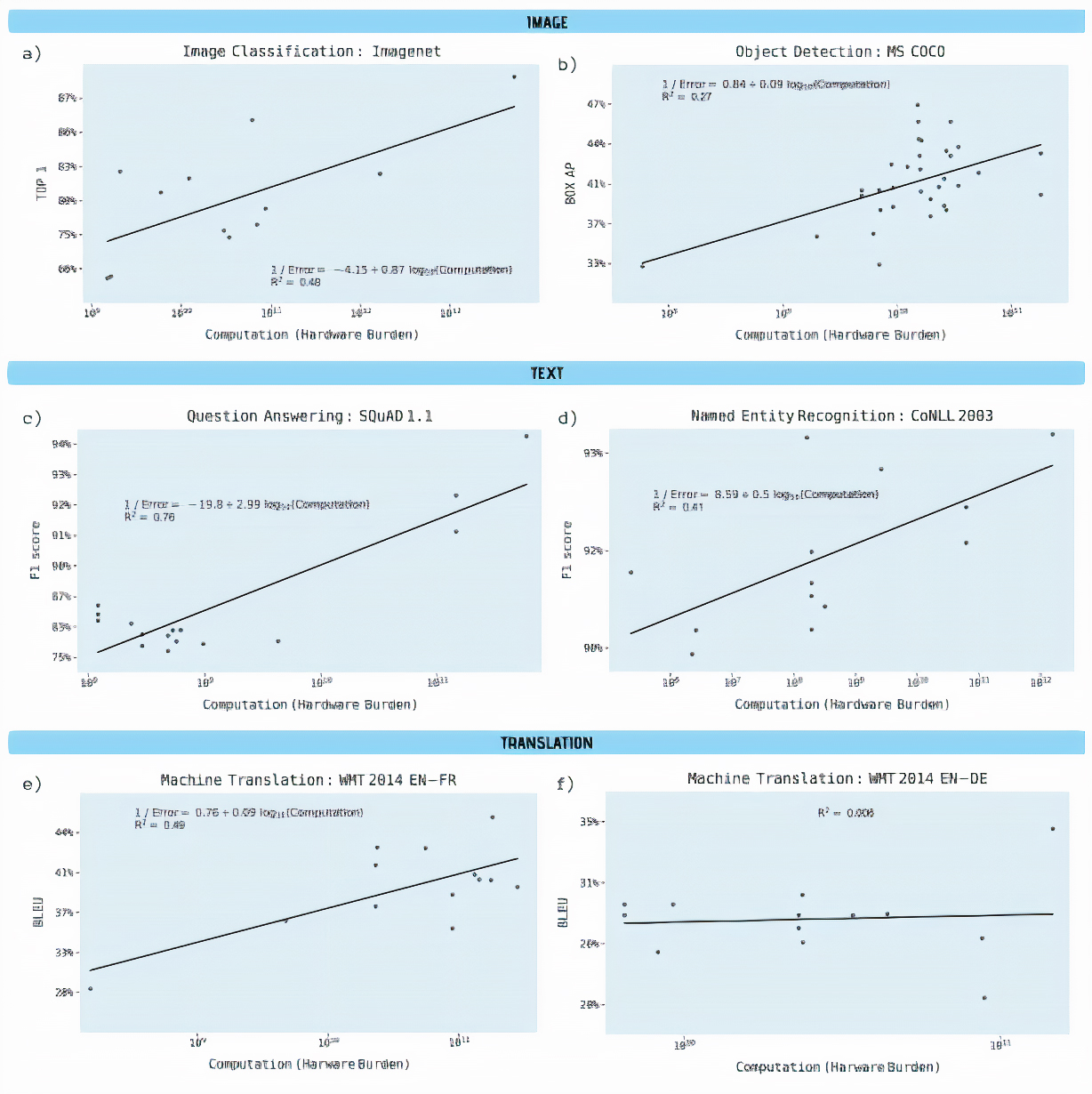
Vedci v štúdii urobili dve analýzy výpočtových požiadaviek, ktoré odzrkadľovali dva typy dostupných informácií: Výpočet na sieťový priechod alebo počet operácií s pohyblivou rádovou čiarkou vyžadovaných pre jeden priechod v danom modeli hlbokého učenia.
Druhá analýza bola Hardvérové zaťaženie, resp. výpočtová schopnosť hardvéru použitého na trénovanie modelu. Vypočítala sa ako počet procesorov vynásobený výpočtovou rýchlosťou a časom. Vedci pripúšťajú, že aj keď je to nie je najpresnejšia miera výpočtu, v správach, ktoré analyzovali, sa to uvádzalo vo väčšej miere ako iné referenčné hodnoty.
Detekcia objektov, rozpoznávanie entít a najmä strojový preklad ukázali veľké zvýšenie hardvérovej záťaže s pomerne malými zlepšeniami vo výsledkoch.

Vedci uviedli, že trojročné vylepšenie algoritmu zodpovedá zhruba 10-násobnému zvýšeniu výpočtového výkonu. Výsledky štúdia jasne poukazujú na to, že v mnohých oblastiach hĺbkového učenia závisel pokrok vo vzdelávacích modeloch od veľkého nárastu použitej výpočtovej sily.
Výskumníci potom extrapolovali projekcie, aby pochopili vzťah medzi výpočtovej sily potrebnej na dosiahnutie rôznych teoretických referenčných hodnôt s pridruženými ekonomickými a environmentálnymi nákladmi. Podľa najoptimistickejších simulácií by zníženie chybovosti klasifikácie obrázkov na serveri ImageNet vyžadovalo ďalších 105 výpočtov!
V súhrnnej správe odhadujú, že model odhalenia falošných správ z University of Washington Grover stojí približne 25 000 dolárov na zaškolenie hĺbkového učenia za dva týždne. Vedci z University of Massachusetts v Amherste zistili, že množstvo energie potrebnej na výcvik a vyhľadávanie určitého modelu učenia zahŕňa emisie približne 283 950 kg oxidu uhličitého. To zodpovedá takmer päťnásobku emisií za životnosť priemerného vozidla v USA.
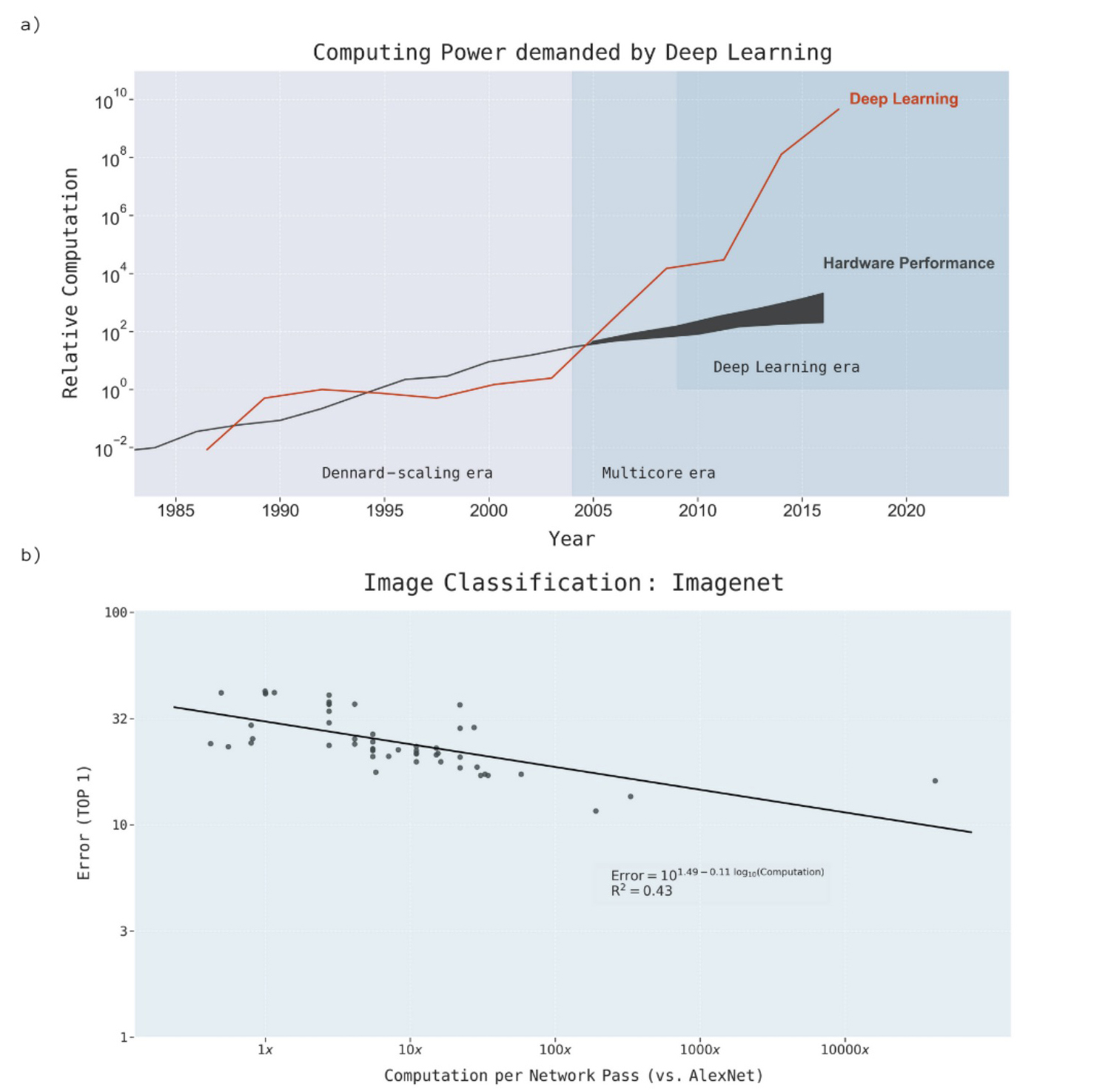
Vedci v štúdii píšu, že vyriešenie problému výpočtových požiadaviek ekonomicky prijateľným spôsobom si bude vyžadovať efektívnejší hardvér, účinnejšie algoritmy alebo iné vylepšenia.
Závery štúdie sú jasné. Blížime sa k výpočtovým limitom hĺbkového učenia. To však vôbec neznamená, že sme sa ocitli v slepej uličke. Vývoj ide raketovým tempom dopredu a na prelomové objavy sa môžeme čakať aj v budúcnosti. TECHBOX vás bude nimi sprevádzať.