
Pozrite si
Keď sa povie strojový hlas, každý si v duchu predstaví umelý, skreslený, neprirodzene znejúci hlas, ktorý jednoducho neznie ľudsky.
Výskumníci z Google teraz našli spôsob, ako bude počítačom generovaná reč znieť pre ľudí prirodzenejšie. Niektorí členovia z tímu Google pre výskum mozgu a strojov napísali blog, kde popisujú akým spôsobom sa to dá urobiť. Zároveň firma Google oznámila beta vydanie služieb Cloud Text to Speech, ktoré ponúkajú zákazníkom rovnakú hlasovú syntézu, akú používa Google Asistent.

Textové prezentácie vytvorené počítačom by tak urobili prirodzenejšie hlasové prejavy v aplikáciach, digitálnych službách, či ostatných zariadeniach využívajúcich hlasovú komunikáciu.
Nové metódy sa opierajú o Tacotron 2, systém umelej inteligencie (AI) používajúci neurónové siete, ktoré boli naučené na napodobenie ľudskej reči. V prvej sérii testov znel hlas z Tacotronu oveľa lepšie ako bežné hlasové služby, nedokázal imitovať stres a intonáciu. Tieto prozódy, ako sa tieto zvukové vlastnosti volajú v lingvistike, sa napokon podarilo docieliť vložením štýlu zo zaznamenaného klipu ľudskej reči.
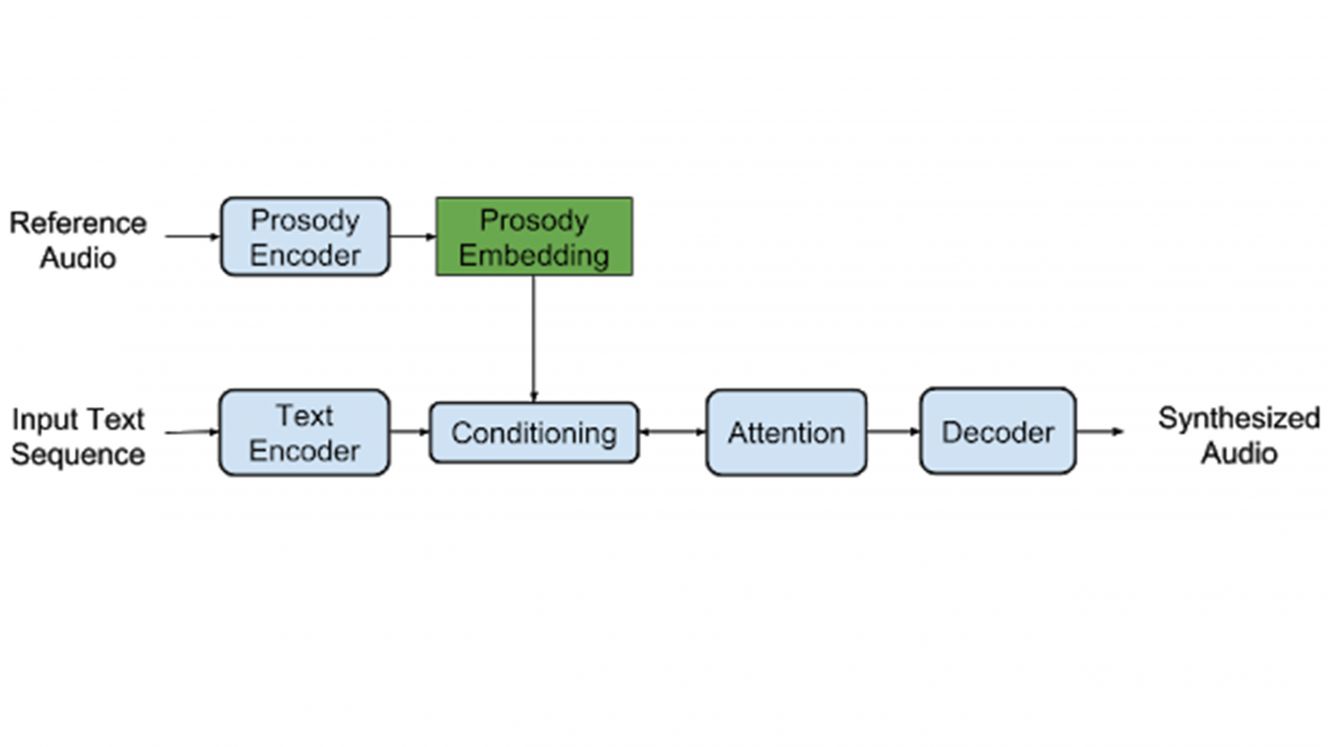
Princíp Tacotronu 2, spodnú polovicu obrázku tvorí pôvodný model Tacotron.
„Táto integrácia zachytáva charakteristiky zvuku, ktoré sú nezávislé od fonetických informácií a idiosynkráznych znakov reči – to sú atribúty ako je stres, intonácia a časovanie,“ povedal výskumník Yuxuan Wang. „V časovom intervale môžeme použiť toto vloženie na vykonávanie prozodického prenosu, generovanie reči v hlase úplne iného rečníka, ale zachováme prozodiku odkazu.”
Prvá metóda prenosov prozodícii tak závisí od napodobňovania reči podobnej dĺžky a štruktúry vety. Druhá úspešná metóda sa dosiahla prenášaním reči v potrebnej intonačnej a stresovej štruktúre bez potreby zvukového podkladu napodobňovaného tónu, či podobnej dĺžky. Do Tacotronu pridáva algoritmus nezvyčajnej pozornosti a núti ho, aby delegoval vkladanie prozódy každého hlasu ako lineárnu kombináciu pevnej sady základných štýlov. Vedci ich nazvali ako GST (Global Style Tokens) – globálna architektúra štýlov.
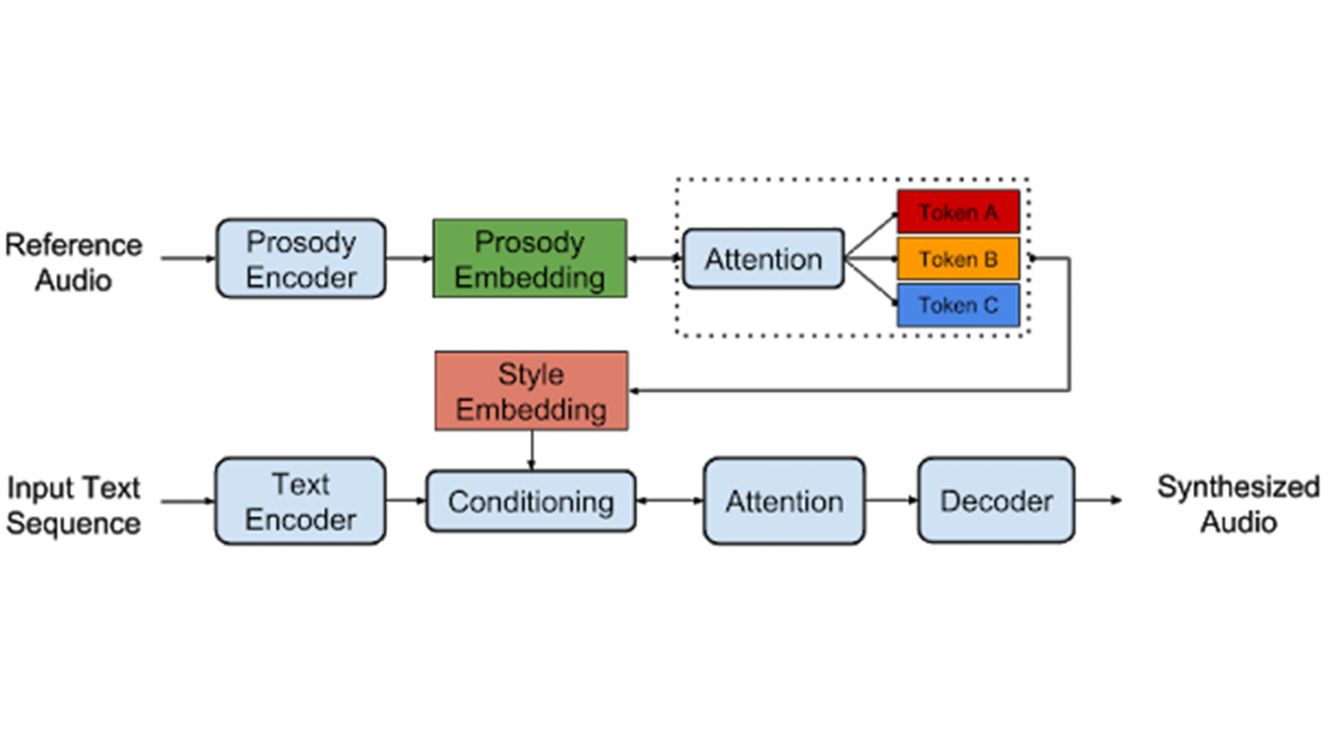
Príklad, ako sa GST rozkladajú na štýlové „žetóny“ (Token A, B a C.)
Vedci Wang a Skerry-Ryan označili výsledky práce ich tímu za sľubný výsledok, ktorý otvorí cestu pre dizajnérov hlasových interakcií, aby mohli používať svoj vlastný hlas na úpravu syntézy reči.
https://youtu.be/eegp9AaqbxE
Táto technológia by mohla napríklad “poludšiť” aj hlas asistentky v Google Assistant. Minulý rok totiž Siri od Apple získala hlasový update a Alexa od Amazonu dokáže vďaka know-how od SSML pridať do hlasu asistenta šepot, pauzu, alebo údiv.
Ani sa teda nenazdáme a spoznať to, že sa rozprávame s počítačom nebude vôbec ľahké a už teraz sa môžeme tešiť na deň Blbec, keď nám pekne írečito a od srdca vynadá šofér auta, ktorému sme nedali prednosť. Až na to, že auto bude autonómne riadené a hlas bude patriť robotu.
Zdroj